Visual Word Sense Disambiguation (VWSD) is a multimodal NLP task. Given a context sentence, a target word, and a set of candidate images, the goal is to identify the image that most appropriately represents the intended sense of the target word.
The project
The baseline approach uses a pre-trained CLIP model to compute similarities between the context and candidate images, selecting the image with the highest score. As an additional experiment, this work evaluates CLIPSeg, a CLIP-based image segmentation model. The intuition is that segmentation is closer to visual disambiguation: the model must focus on the relevant image region and separate it from surrounding content. For multilingual test data, contexts are translated with dedicated Italian and Farsi translation models.
Quantitative results
The first English test with CLIP reached 58.31% accuracy, confirming CLIP's usefulness in zero-shot settings. CLIPSeg reached 63.28%, outperforming the baseline by 4.97 percentage points. Running CLIPSeg directly on Italian and Farsi contexts without translation led to poor results, with 18.03% accuracy for Italian and 9.5% for Farsi. Translation improved both cases substantially, reaching 50.49% for Italian and 32% for Farsi.
Qualitative analysis
Saliency maps
Saliency maps help interpret which image regions influence the model's predictions. Here, the goal is to compare samples where CLIPSeg predicts correctly and baseline CLIP fails, checking whether CLIPSeg's advantage comes from focusing on the parts of the image that actually match the intended sense.
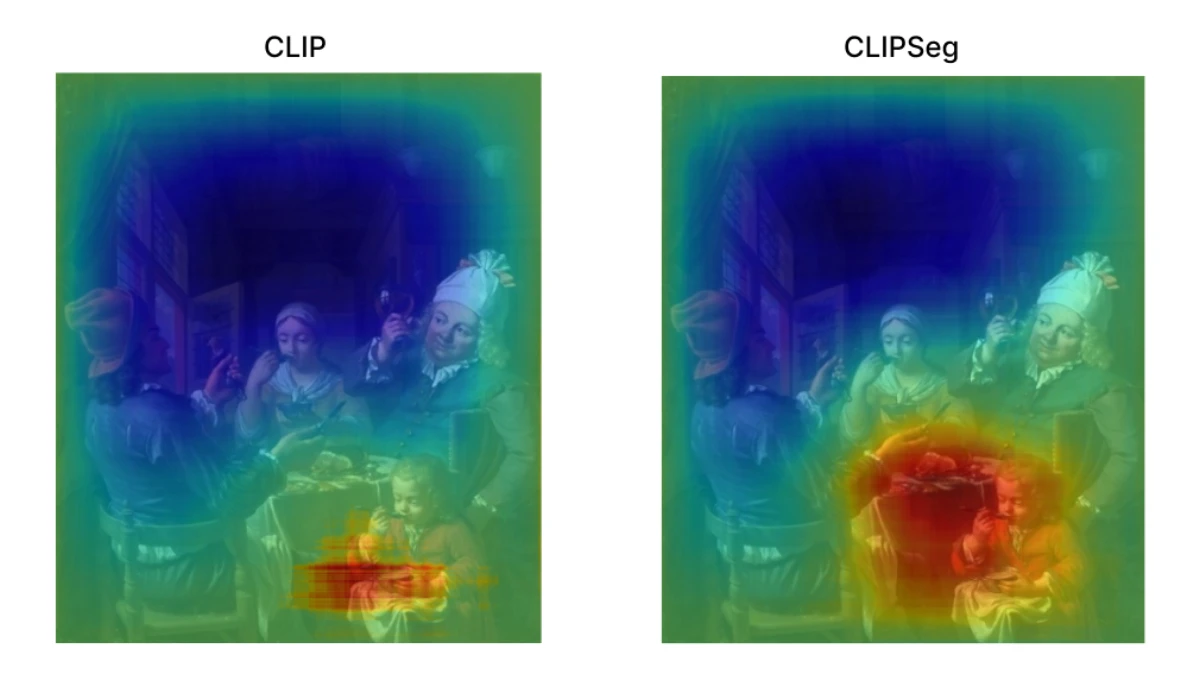
Image segmentation
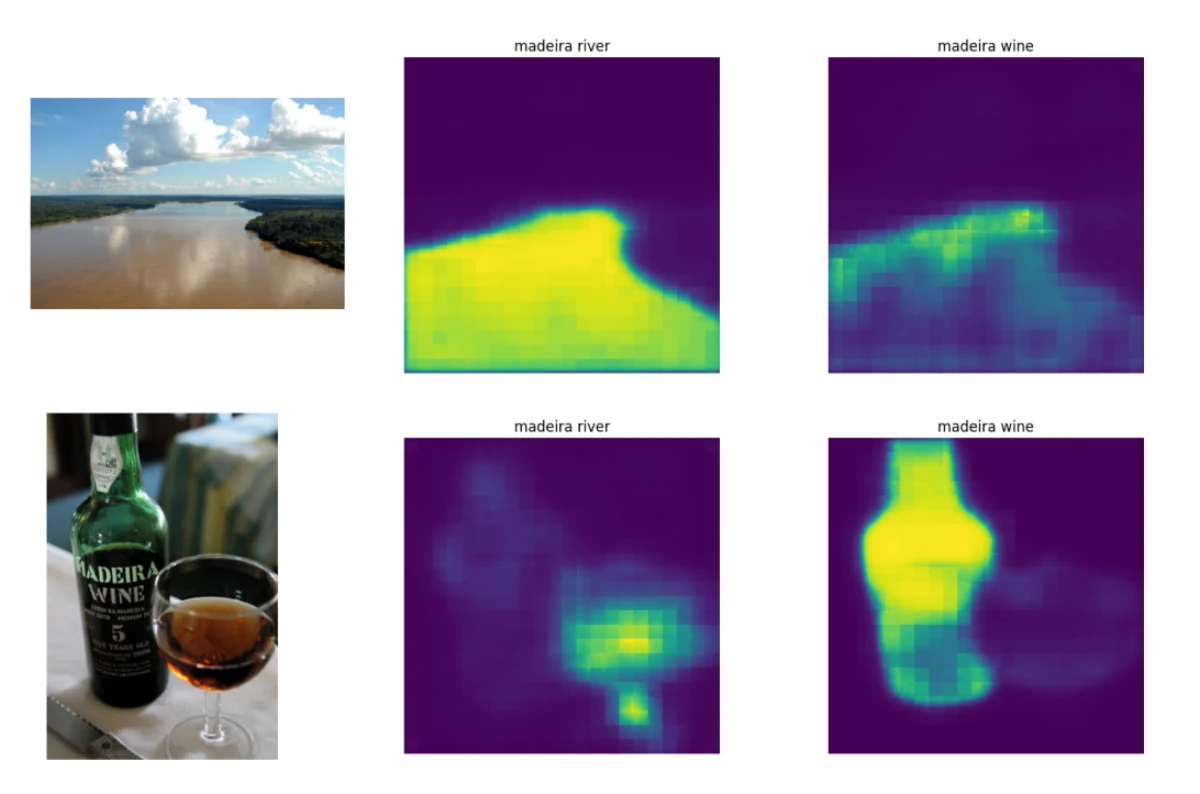
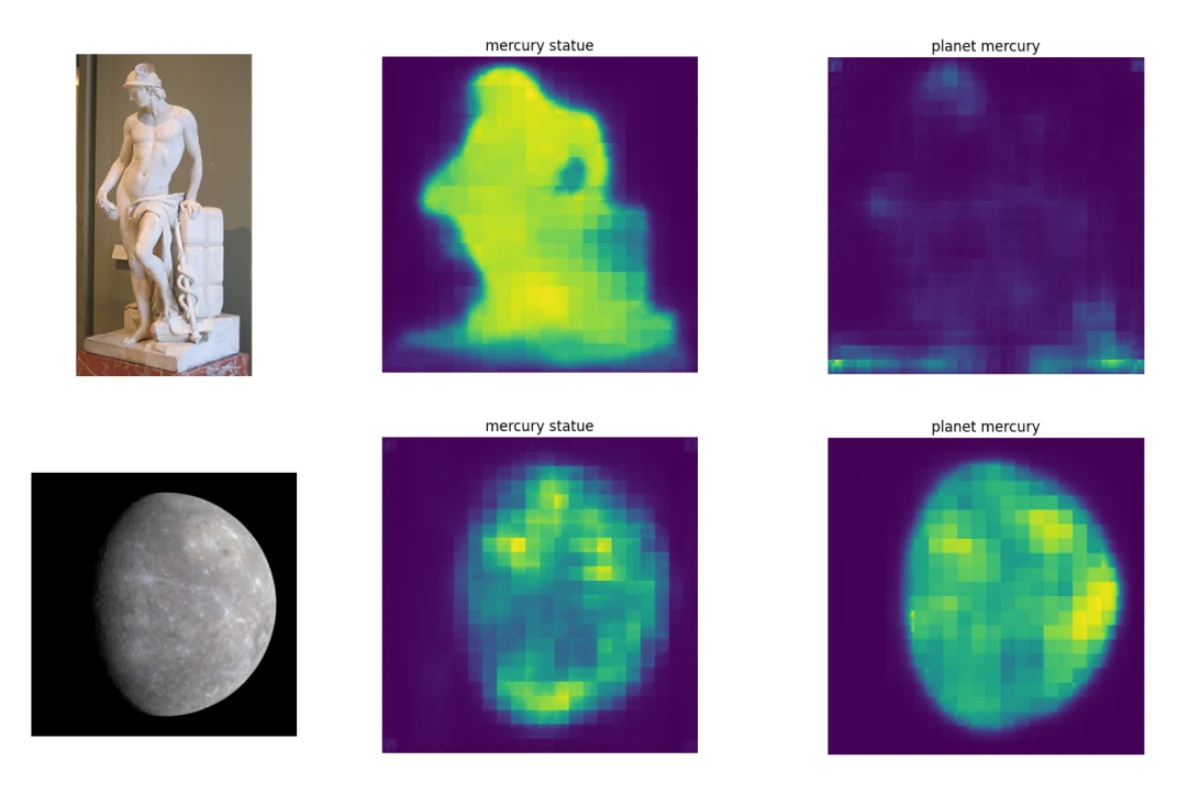
Another experiment compares different contexts for the same ambiguous word and observes how segmentation changes. For example, using "madeira wine" on an image of the Madeira river produces a weaker segmentation than the correct "madeira river" context. A similar pattern appears with the Mercury statue examples, suggesting a useful correlation between segmentation behavior and disambiguation accuracy.