In Natural Language Processing, Word Sense Disambiguation (WSD) is the task of assigning the correct meaning to ambiguous target words given their context. Homonymy disambiguation is a specific instance of this task where related senses are clustered together, producing a coarse-grained WSD setup. In this context, two words are homonyms if they share the same lexical form but have unrelated meanings.
BERT-based models such as GlossBERT have been extensively used for this family of tasks because contextualized embeddings can capture word senses. This project describes a series of experiments with BERT-based architectures, focusing on fine-tuning choices and the practical operations needed to make the classifier behave well with a large sense inventory.
Proposed architecture
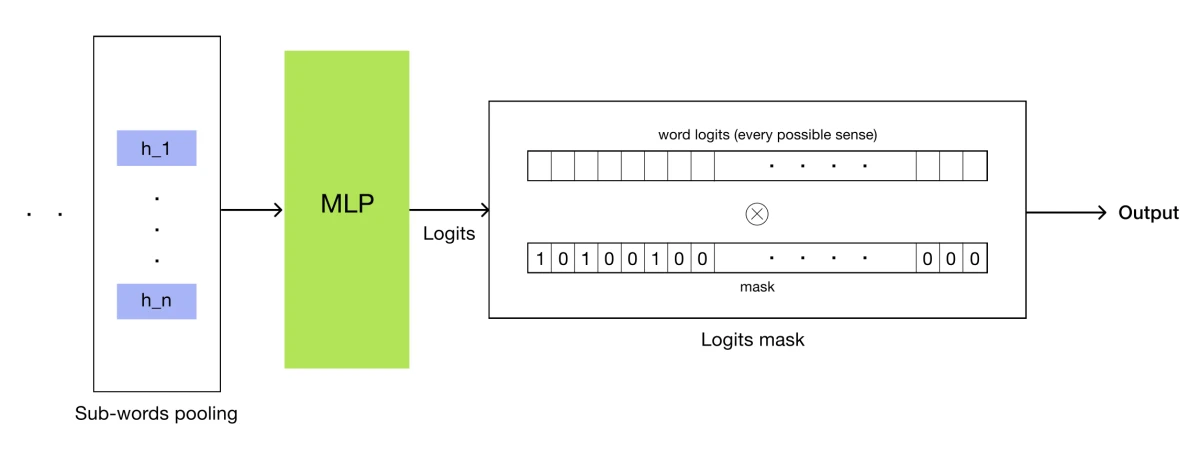
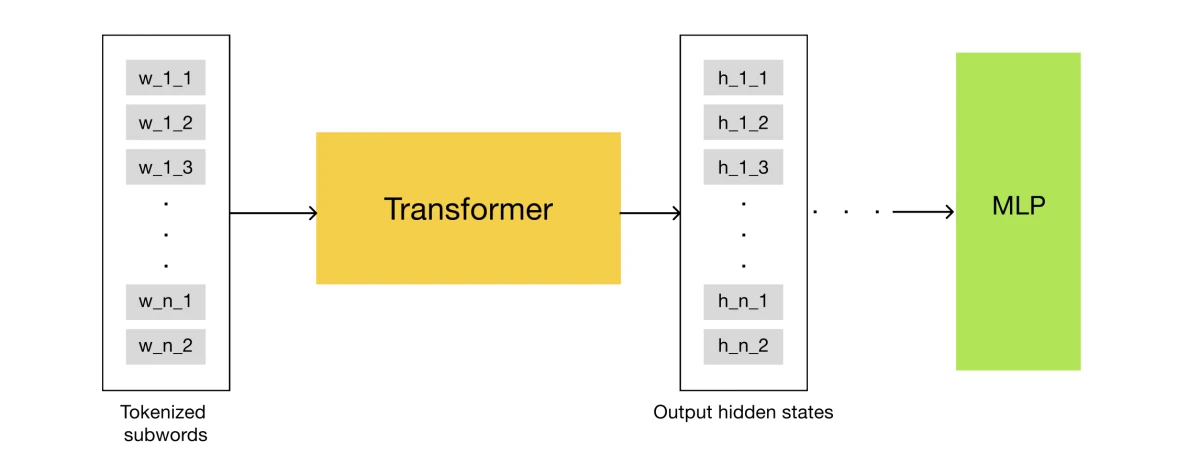
The proposed architecture consists of two main modules: DeBERTa, used to extract word embeddings for each token, and a classifier head, implemented as a Multi-Layer Perceptron. The classifier consumes the transformer's embeddings and outputs logits for each possible class. The model also adds operations at both the embedding level and the logits level.
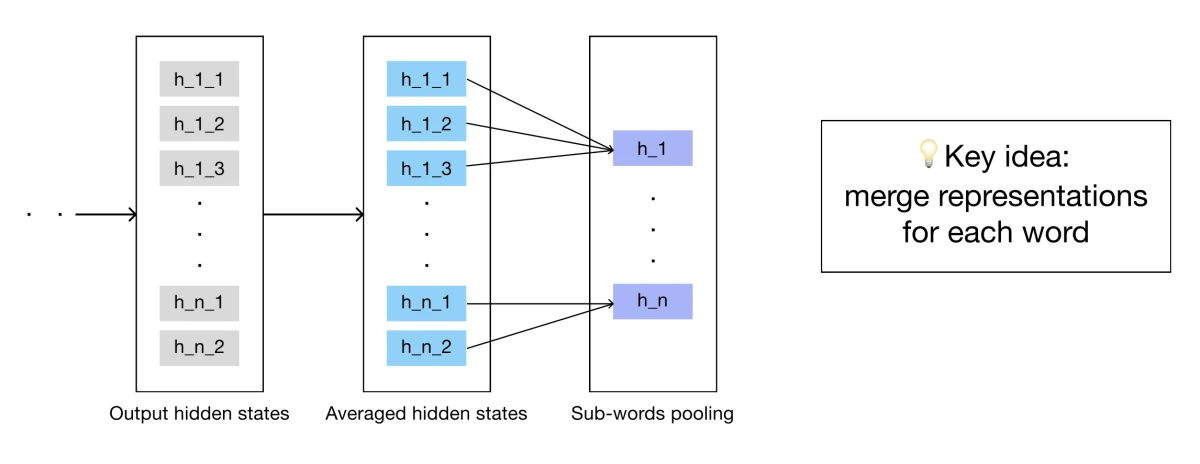
Averaging hidden states
Different transformer layers encode information at different levels of abstraction. The proposed method uses the average of the last four hidden states to build a richer representation for each token before pooling the target word.
Sub-token pooling
During tokenization, some words are split into multiple sub-tokens. After the transformer pass, the resulting sub-token embeddings for each word are averaged to obtain a single representation for the complete word.
Logits mask
This task can involve thousands of possible senses. To keep the classifier focused, candidate senses for target words in the dataset are used to create a logits mask. Candidate senses receive ones and all other senses receive zeros, constraining the model to score only plausible meanings for the current target.